
My University Thesis - Full Text Indexing
18 years ago as my final year project I wrote a full text indexer and business plan for a business in which to develop an online service to allow people to search through open source mailing lists. The service was to be called OSDigger as it allowed you to dig through Open Source mailing lists. My inspiration was what you could do with Dejanews and usenet groups.
The other day, whilst digging through an old hard disk looking for something, I stumbled across the code and my original thesis. Looking back at it now, the thesis itself seems to be more impressive that the code. In fact, it looks like half the code may indeed be missing, no idea why.
But either way it is a fun look back at what the internet and state of computing was like at the time. My main bibles for this at the time were ‘Managing Gigabytes’ by Bell, Witten, and Moffat. And Modern Information Retrieval by Baeza-Yates and Ribeiro-Neto. I remember in Managing Gigabytes that they were talking about running the code on 1993-era Sun SparcStation 10 workstations that used 50Mhz SuperSPARC processors and supported a max of 512MB of RAM. I had at my disposal a machine with a 300Mhz Intel Pentium and 2GB of RAM! An order of magnitude more power than they had at the time. And looking back at that now, I can buy that power for about £10 and have it in my pocket.
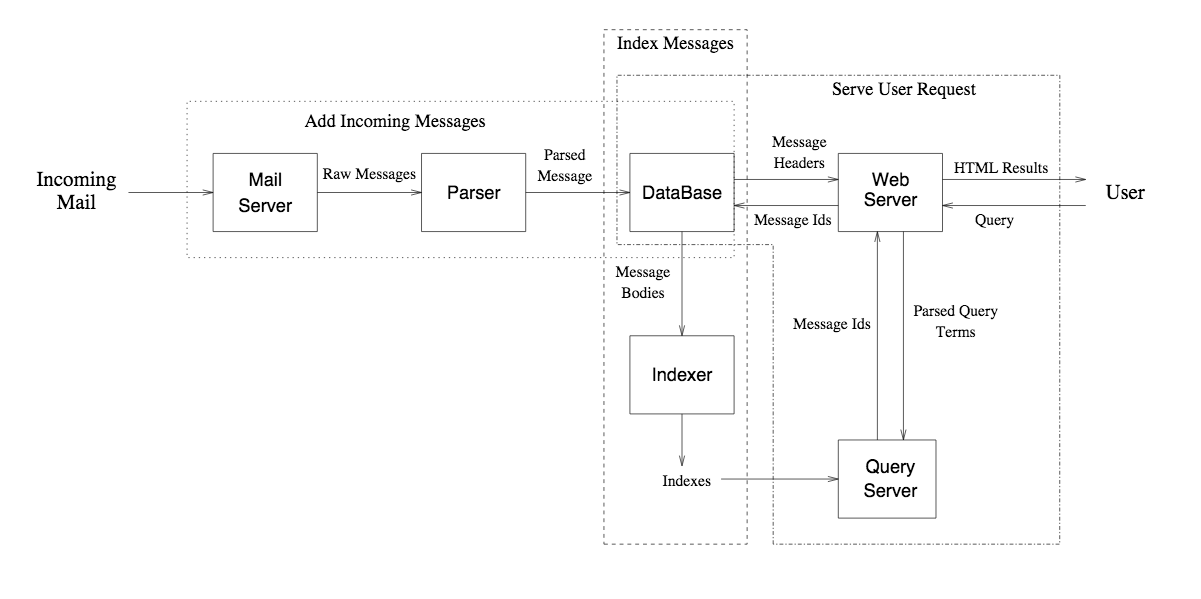
I was also keeping an eye on an interesting startup web crawler from Stanford called ‘Backrub’ by two engineers Sergey Brin and Lawrence Page. They published a paper called ‘The anatomy of a Large-scale hyper textual web search engine’ which outlined the architecture of ‘barrel’s that I adopted for OSDigger. This was a means of being able to construct an inverted index (the main data structure of information retrieval at the time) piecemeal with limited RAM. It could also be parallelised and run over a cluster of servers if needed. Backrub went on to become Google, and Brin and Page took over the online world.
We managed to even get a beta of the site working, and you could search through mailing list posts. There was even a two-stage search feature in which it would suggest additional terms to narrow your search down.
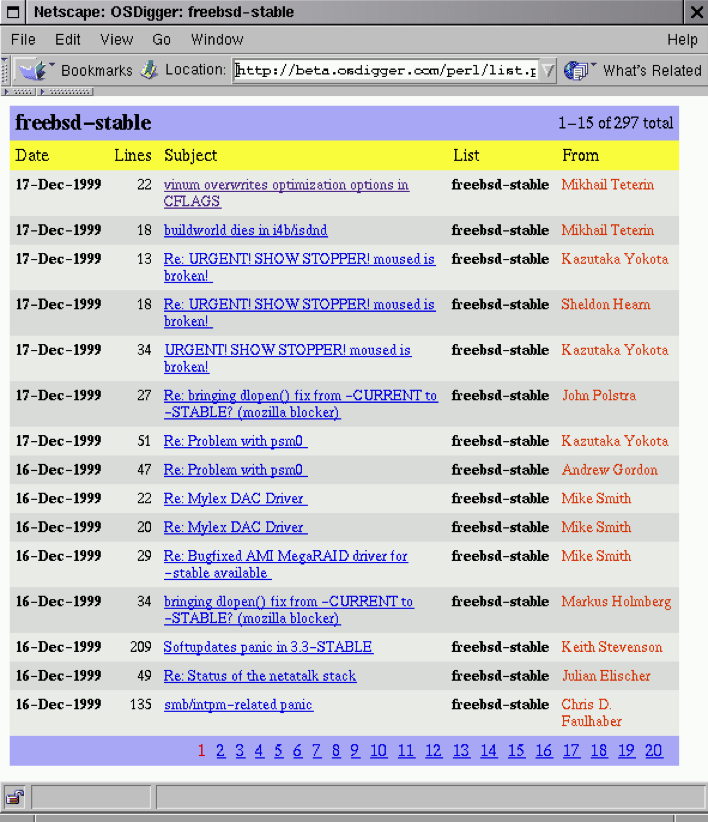
In the end though, after graduating, we all went our separate ways and we never had to time to really take the site to its full commercial launch. Which was a shame looking back at it, but still, it was a good trip!
Most recently I got a chance to dig back into this part of my brain, as I wrote an offline full-text search function for a mobile app I’m working on. We were able to replicate the performance and ranking of Elasticsearch directly on the phone itself. But that is a story for another day.