
So, firstly, thanks to Alloy for the Magritte reference for the title of this post.
Yesterday, a friend on Twitter, Munch, put out an art challenge:
Well, I'm rubbish at art. But for a bit of fun, decided that rather than showcase my rubbish art, could I instead showcase a computer's attempt at art? What could go wrong? Can I teach a computer to draw a duck and fill in the blank template above?
So, introducing to you the concept of Generative Adversarial Networks ... or GANs for short. Gen...what? These are a type of machine learning neural network that attempt to generate new data (generative) from learning from a series of samples, by trying to out-wit a second neural network (a dversarial).

So how does it work? Let's imagine you and I play a game. Your job is to show me a series of James Bond films some of which are real, and some of which are ones that you have produced yourself. My job is to try and guess which of the films is real, and which is fake. Got it so far?
So firstly, you watch all 26 James Bond films and try to distil down the essence of a James Bond film. What features make it a James Bond film if you had to describe it to someone?
- Athletic male lead, who is a British secret service agent
- Lots of gadgets like X-ray glasses, and camera tape recorders
- Car chases... cars with guns in them etc
- Esoteric villains
- A sexy adversary
- Great music
- etc
Using that list of 'features' of a Bond film, you now produce your own Bond film... you might be good at it you might be bad at it. To start with you are going to be pretty lousy at it on your first attempt.
My job is to look at the film you produce and decide if it is a real Bond film or fake. If it is very easy for me to guess a real one from a fake and I get them all right, then that means you are doing a poor job at making fakes.
The goal here, is for you to keep trying to make fakes to fool me. And my job is to keep feeding back to you how well I can tell the real from the fake. If I can't tell the difference from a real Bond film and a fake one, then you have done a very good job in producing a new, unseen, fake Bond film.
In terms of a machine learning architecture, it looks like this:
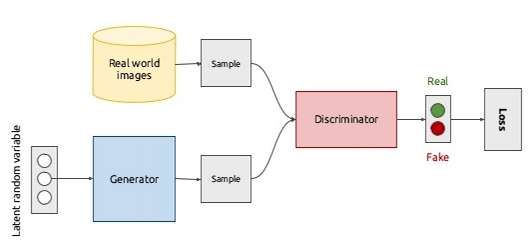
You have one branch at the top (yellow) feeding in real Bond films, and you have a generator at the bottom (blue) creating fakes ones (your job). And you have me, the discriminator (red), trying to tell if they are real or fake. My error rate in judging them, loss , is fed back to the start for the next iteration. Based on that loss, you can determine which features were important or not. ie. if you put a dragon in your Bond film and I feed back that clearly this is not a Bond film you can infer that dragons are not a legitimate element of a Bond film.
Show me the ducks!
So, I needed:
- a working GAN algorithm
- some ducks
For the algorithm, I found one on Github (a code sharing/collaboration site) that I could use for this task. This one had been used originally to try and generate new Simpson's characters, so might be good, as already tuned to cartoons:

I loaded the code into Google Colab , which is another collaborative tool that allows you to run python code on a cluster of computer run by Google. This is helpful as GANs take quite a lot of computing power, and means I could run it faster than I could on my computer at home.
I also needed a bunch of 'real' images of duck drawings for it to use. I search Google for "draw a duck share your art" which is the meme this was from, and downloaded a whole bunch of them:
I uploaded them to where my code could load them and then set the algorithm to run. My first attempt was for 300 'epochs', that is there were 300 iterations of trying to generate duck images and trying to fool the disciminator.
The first attempts you can't see anything duck-like at all, as the generator has started with random data and still not worked out what 'features' the output images should have. Here is 5 samples of 'ducks' from epoch 24:

Not very exciting, huh? Just grey blobs...
As it progresses, it starts to try various colours... and we end up with a nice tweed sort-of colour coming up. Great for cushions perhaps, but still not a duck. Epoch 100:

By the time we get to epoch 250, we are now getting some slight duck-like features show in the images. You can spot the yellow feet and beak emerging:

But by the time we get to epoch 300, it's all gone wrong again:

What happened?! Well it turns out it looks like the algorithm kinda overshot the mark. There is actually a graph produced of the learning losses of both the generator and the discriminator:
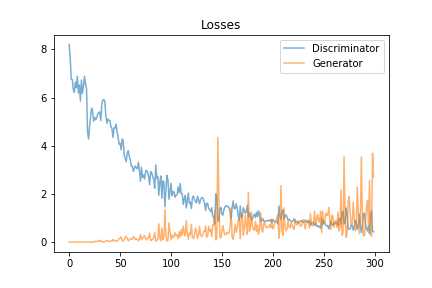
You can see that they were converging until around epoch 250, then the generator kinda went a bit nuts.
So, I decided to run it again, reducing the 'learning rate' of the algorithm. This means it will learn a bit slower, but hopefully won't overshoot as much. I left it running overnight for 600 epochs to see how it got on. The graph of the learning looks a lot more positive this time. As you can see by the time it got to the end it was still pretty stable. It looks like it still has a bit of a 'wobble' around 300, but then seems to stabilise again.
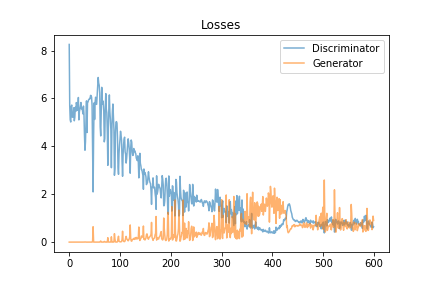
So... the moment of truth... let's see what our ducks looked like!
Here is a sample of them, from near the end at iteration 589:

Whilst I don't think I will be winning any awards with these ducks, I think it has certainly managed to get along the right tracks!
I think due to the high variance of input duck images, it had a hard time trying to work out what a duck should look like. With more samples, and perhaps more iterations it might do better. There are also a number of parameters to the algorithm that can be tuned to try and get better results. But for a quick un-tuned attempt, I'm pretty impressed.
And for Coil subscribers below you can see a really cool animation of the 'evolution' of the algorithm learning what a duck is :)
Part II of this adventure continues with: Ceci n'est pas un Matt - Machine Learning and Generative Adversarial Networks - Part II
Go Top
comments powered by Disqus